Incidence Rates
Explanations & examples: Calculate the incidence rates of one or more groups and compare two rates to see if they could be either equal or are significantly different from each other. For
each group, enter the total number of cases (events) that was observed throughout the period of the study and the total person time of that group. The rate of the
group is then these two values divided. The incidence rate is usually "per 1000", but not necessarily. This can be changed with the "per" button. If the rate is, for
ex. 13 per 1000, this means that if you took 1000 persons from the group and followed them for 1 year, 13 persons would get the disease / outcome.
Calculate the incidence rates of one or more groups and compare two rates to see if they could be either equal or are significantly different from each other. For
each group, enter the total number of cases (events) that was observed throughout the period of the study and the total person time of that group. The rate of the
group is then these two values divided. The incidence rate is usually "per 1000", but not necessarily. This can be changed with the "per" button. If the rate is, for
ex. 13 per 1000, this means that if you took 1000 persons from the group and followed them for 1 year, 13 persons would get the disease / outcome.
The cases are the ones who got the outcome / disease at some point in the medical study or trial. The different groups are usually groups that were exposed to different levels of the exposure of interest. Often there are only two groups in such a clinical trial; namely the "exposed" (group 1) and the "unexposed" (group 2). The total person time for each group is calculated by adding all the individual times together that each of the participants was observed in the study. If an individual in the group got the outcome / disease at some point in the study, there will be added 1 to the cases and the total time of the group will be incremented with the amount of time that the individual was observed until he/she got the disease. If the person didn't get the outcome, then the no. of cases will not be incremented by 1 and the person's time in the study will be added to the group's total time. When comparing and testing two incidence rates to see if they are significantly different, the two groups in question can be selected via the drop down selector menus. Then the ratio of the two rates of the groups is being calculated, known as the incidence rate ratio (IRR). If the value of IRR is significantly different from 1, then the null hypothesis H0 must be rejected. The null hypothesis claims that the two rates are equal (there is no statistically significant difference between them). A different H0 can also be tested, for ex. that the rate of group 1 is the double of the rate of group 2. This is done by entering IRR = 2 into the input field of H0. This new H0 will then also be rejected or not rejected depending on whether the p-value is below or above 0.05. That is; if you are operating with a five percent significance level, which is most common. The weighted estimate (or weighted average) of all the groups is being calculated as the combined incidence rate of all the groups involved, taking into consideration the "weights" of each group. A rate of a group will "weigh" more in the calculation of the weighted estimate if there are more persons in this group relative to the others. The crude rate is the incidence rate of all the involved groups mixed together, if there had been no partitioning into groups. In other words all the cases of all the groups added together divided by all the times of all groups added together. For more info about the processes and formulas used in the calculations, please see the page medical statistics formulas. Input types: If you already have calculated the no. of cases and the total exposure time in years for each group, then you should choose the default input type "1 × 2 tables". If, on the other hand, you have the data as unanalyzed data in a text file, you should choose input type "raw data". Furthermore; if the data in your text file is in the following format:  then you should also mark the click option "data in file is in columns" before copy/pasting into the table or reading from a data file. If the data in your text file have the following format;  Then you should instead click the check mark "data in file is in rows" before copy/pasting or reading from a data file. Example:In this example(a) we want to investigate whether the rate of getting depression after a stroke differs in the group that got anti-depression rehabilitation (group 1) and the group that didn't get this treatment (group 2). In the treatment group (group 1) there were 75 people who got a depression and the total number of person-years for this group was 6609 years. In the non-treatment group (group 2) 566 people got a depression and the no. of person-years for this group was 30554 years. 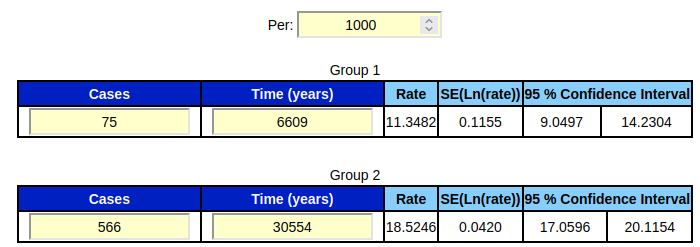

The incidence rate of group 1 is 11.3482 with a 95 % confidence interval of [9.0497 : 14.2304]. The incidence rate of group 2 is 18.5246 with a 95 % confidence interval of [17.0596 : 20.1154]. It is noticed, that the interval of group 2 is narrower than the interval of group 1. This is because there were more people in group 2 than in group 1, therefore the standard error decreases, the precision increases and the interval narrows. By comparing the incidence rates of the two groups it is noticed that neither of the rates is included in the confidence interval of the other rate. And furthermore, there is no overlap between the confidence intervals. When there is no overlap between the intervals, like here, the two rates could never be equal to each other and we can therefore already now reject the null hypothesis H0, which states that the two rates are equal (i.e. the IRR between them could be 1). So in this case with no overlap in the intervals we don't actually have to make a test to see if the rates could be equal, since we know already now beforehand, that the p-value in the z-test will be below 0.05. If you do wish to make the z-test anyway, the z-value is z = 3.9879 and the corresponding p-value is p = 0.0001. The value of the incidence rate ratio is IRR = 0.6126, which we now know is significantly different from 1 on a five percent significance level. If the IRR hadn't been significantly different from 1, the p-value would have been above 0.05 and we couldn't reject the null hypothesis that the rates could be equal. The interpretation of the IRR value of 0.6126 is that the treatment group (group 1) has a (1 - 0.6126) × 100 = 38.74 % lower risk of getting the outcome (depression) compared with group 2. (a) Hou et al.: Effects of Stroke Rehabilitation on Incidence of Poststroke Depression: A Population-Based Cohort Study |
|
Per: |
Decimals:
|
|||||||||||||||||||||||||
|
No. of groups:
|
||||||||||||||||||||||||||||